Apache Solr - The search platform

Apache Solr is an open-source, Java-based, search server built on top of Apache Lucene by the Apache Software Foundation. It is highly scalable, reliable, fault-tolerant and distributed and designed for powerful document retrieval applications. Solr is based on open standards and uses HTTP URLs for its queries. The responses from these queries are usually JSON, but can also be XML, CSV or any other common formats. Any client such as mobile devices, web browsers and rich client applications can easily use the search capabilities of Solr. The entire search process is simple, you put documents into Solr as JSON, XML or binary format (known as indexing) and then make HTTP GET requests to query it.
Solr is also packed with a whole lot of cool features. It is capable of powerful text matching including phrases, wild cards, joins and much more. It is optimized for high-volume traffic, many popular internet companies make use of Solr for their search engines - some of them are Macy’s, Netflix and eBay. It has an extensible plugin architecture - you can develop your own query or index plugins to customize the default query and indexing behaviour. Solr comes with a web UI for easy monitoring and administration of the cluster. It ships with auto-complete and spell-check features and supports Rich document parsing out of the box making it easy for indexing PDF and Word documents.
Solr Concepts
Documents, Fields & SchemaSolr's basic unit of information is a document. The document consists of information about something. For example, a document about an employee can contain information about first name, last name, age and employee ID.The document consists of many fields. These provide a more specific piece of information. The age field conveys how old the employee is. Fields can be of different types – text, floating point and number. Solr stores information about the fields and field types in a schema file. If you define the document schema correctly, Solr will be able to interpret them correctly giving you get better results when you perform a query.
IndexingYou provide a lot of information or documents to Solr for searching. This process of providing information to Solr is known as indexing. When you feed information into the Solr, it creates an index which can be referred to later when you make a query. By adding content to an index, we make it searchable by Solr. Solr index can accept data in different forms such as CSV, XML, JSON files, data from tables in databases and common file formats such as word and PDF.
There is a common data structure for the data that is being fed into the Solr index. A document consists of several fields each with a name and content which may sometimes be empty. One of the fields is a unique ID which is not strictly required by Solr. If the field is defined in the schema associated with the index, then Solr will apply the analysis steps specified for the field to the content. If the field is not in the schema, it is ignored or mapped to a dynamic field definition.
QueryingWhen you ask a question to retrieve a piece of information from Solr it is known as querying. The indexing makes the query faster. Instead of going through all the documents one by one, Solr can use the index to find the matching documents or information.
Let's look at the steps and components involved in Solr searching. When a user runs a search, the request is processed by the Request Handler. The request handler defines the logic to be used when Solr process a request. There are many request handlers available in Solr, some of them process the search requests while others process indexing operations. To process the search query, the request handler calls the Query Parser. The query parser interprets the keywords and the parameters involved in the query. The input to the query parser includes:
- Search term: The keyword to be searched in the index.
- Parameters for fine-tuning: Parameters to filter or rank search results.
- Parameters for controlling response: Parameters to limit or order search results.
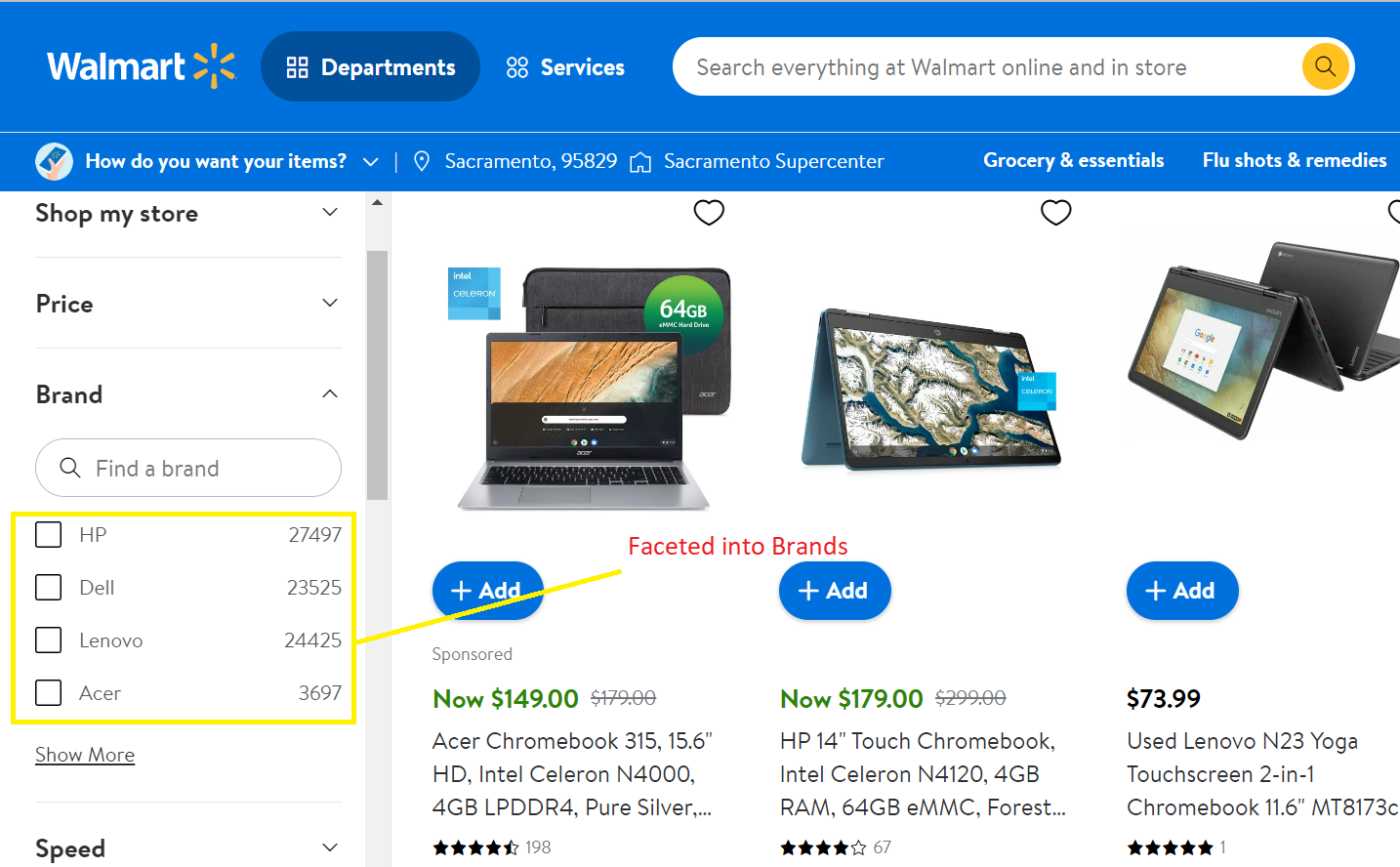
Faceting is the grouping of search results into categories. Within each group, Solr also gives the number of results.These particularly help users that are looking for a specific group in a large result set. A typical example is the search results from e-commerce sites where the products are grouped based on brands, price range and various other parameters.

Nothing here yet

Joyal Baby
16 November 2022• 10 min readExplore a treasure of technical blog posts on Android, Big Data, Cloud, Python, and More!
© 2026 Nervo Tech. All Rights reserved.