Mastering Solr - Essential Technical Terms

You must have got an overview of Apache Solr in the previous post. Like any complex software system, Solr also comes with a set of technical terms and jargon that can be overwhelming for new users. To effectively use Solr, it is important to understand these terms and how they relate to the platform's features and capabilities. In this post, let us discuss some common technical terms you might encounter while dealing with Solr.
Apache LuceneApache Lucene is a free and open-source full-text search engine written in Java. It provides a set of APIs for indexing and searching text data and offers features such as fuzzy searching, boolean queries, phrase searching, and more. Lucene works by creating an index of text data, which can be used to quickly search and retrieve results based on a user's search query.Apache Solr is built on top of Lucene and provides additional features such as distributed search, sharding, spell-checking, faceted search and much more. It also offers a REST-like API for interacting with the search engine, making it easier for developers to integrate search functionality into their applications.
Solr Core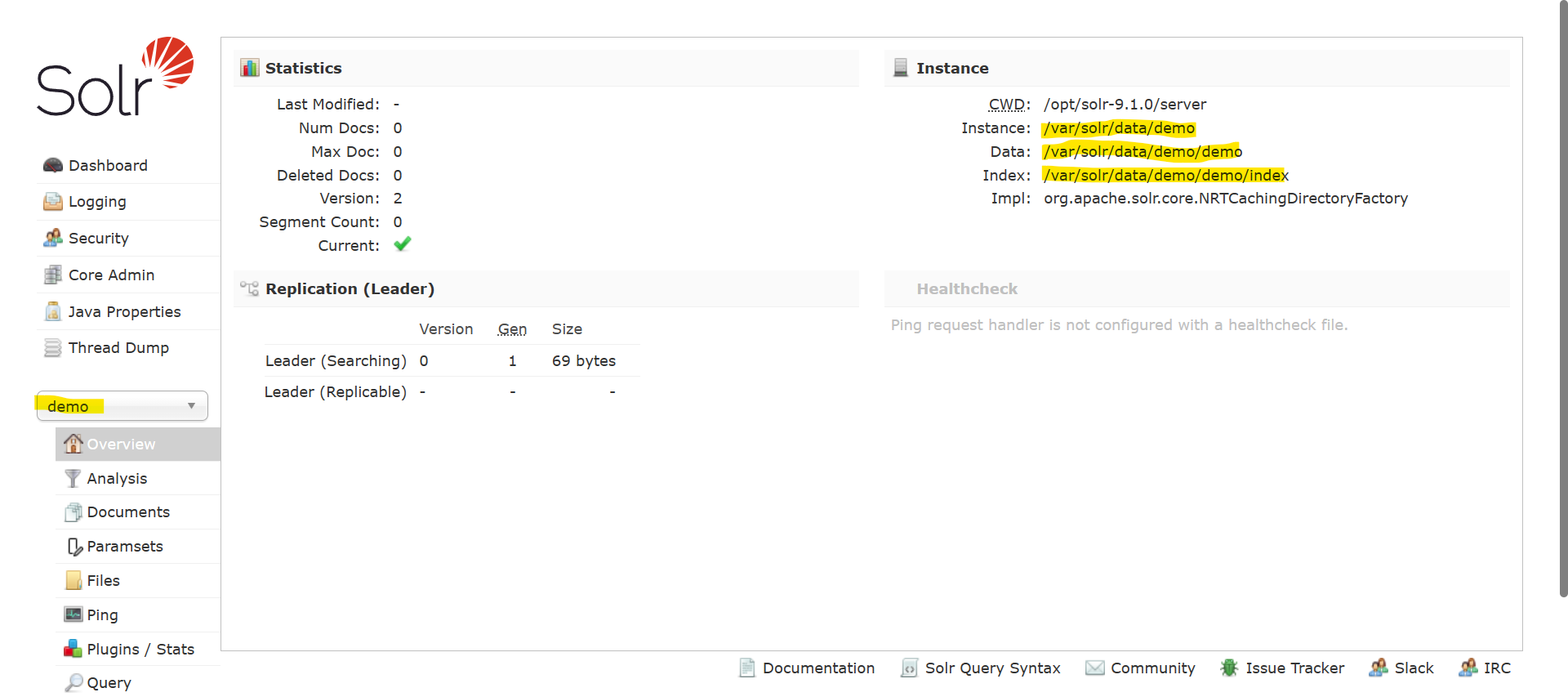
Solr core actually represents an index along with all its configuration files. It can be thought of as a standalone Solr instance, with its own set of index files, configuration files, and query handlers. A Solr server can host multiple cores, each with its own unique configuration and search index. The main benefit of Solr cores is that they allow different indexes to be hosted on a single Solr server, while still providing separation and isolation. This can be useful in scenarios where multiple indexes need to be managed and searched independently.
Each core in Solr has its own set of configuration files, including the solrconfig.xml file, which defines the settings and behaviour of the core, and the schema.xml file, which defines the fields and field types in the core's index. These files are stored in a directory that is named after the core.
SolrCloudSolrCloud is a distributed and scalable collection of multiple Solr instances. Together they are referred to as the SolrCloud. Here, the search index is partitioned among each Solr server and queries are automatically routed to the appropriate nodes. This allows SolrCloud to scale horizontally as new nodes are added to the cluster, providing improved performance and high availability. SolrCloud uses a distributed configuration that allows all nodes in the cluster to have the same configuration files. This makes it easy to manage and deploy changes to the search configuration across the entire cluster. In addition, SolrCloud provides automatic failover and replication of search data, so that in case of a node failure, queries can still be processed.
CollectionSolr collection is a container that holds the documents and the metadata for searching the index. A collection contains several documents that can be searched using Solr. A document is a unit of data that represents a searchable item. Documents are typically stored in structured formats, such as XML or JSON. A document is composed of one or more fields, which are the basic units of search in Solr. A field is a named attribute in a document, such as title or author. Fields can be of different types, such as text, integer, date, or boolean.
ShardShard can be defined as a subset of documents in a collection. A collection can be divided into multiple shards with each shard residing on a separate server or node. Each shard is essentially a self-contained Solr instance with its own index, schema, and configuration.
Some of the benefits of sharding include:
- Scalability: Since sharding divides the collection into multiple parts, Solr can distribute the search and indexing workload across multiple servers or nodes. This allows for horizontal scaling of the search application
- Fault-tolerance: By replicating shards, Solr can provide redundancy and fault-tolerance. If a shard or server fails, the replica can take over and ensure that the search application continues to function.
- Performance:Sharding can improve search performance by reducing the size of the index on each server which can result in faster search queries and indexing.
A replica is a copy of a shard in a collection. Replicas are used to provide redundancy and fault tolerance, as well as to improve search performance by distributing the search workload across multiple nodes. The replication factor is the number of replicas that are created for each shard in a collection. The replication factor can be set when a collection is created and can be adjusted later if needed. For example, if a collection has a replication factor of 2 each shard will have two replicas.

Nothing here yet

Joyal Baby
24 April 2023• 10 min readExplore a treasure of technical blog posts on Android, Big Data, Cloud, Python, and More!
© 2026 Nervo Tech. All Rights reserved.